Learning Articulatory Representations with the MIRRORNET
This website presents audio reconstructions and auditory spectrograms for experiments done in the paper : LEARNING TO COMPUTE THE ARTICULATORY REPRESENTATIONS OF SPEECH WITH THE MIRRORNET
Brief Intro
Experiments to understand the sensorimotor neural interactions in the human cortical speech system support the existence of a bidirectional flow of interactions between the auditory and motor regions. Their key function is to enable the brain to ’learn’ how to control the vocal tract for speech production. This idea is the impetus for the recently proposed ”MirrorNet”, a constrained autoencoder architecture.
The first section in the webpage presents audio samples and corresponding spectrograms from the articulatory-to-acoustic synthesizers developed in the project. The second section presents the results of audio samples and corresponding spectrograms synthesized by the articulatory parameters estimated by the MirrorNet on unseen utterances and speakers from the test split of the XRMB dataset.
1. Articulatory-to-acoustic synthesizer
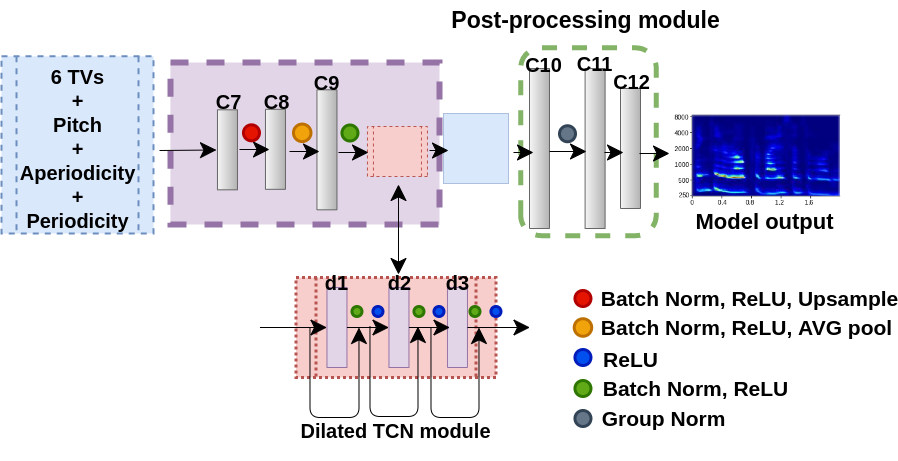
– Auditory spectrograms and audio samples
Tables below show output auditory spectrograms and their corresponding acoustic output obtained by inverting the auditory spectrograms. The two input speech utterenaces are from a male speaker and a feamle speaker in the test split.
| Description | Audio | Auditory spectrogram |
|---|---|---|
| Input Audio (Female) | 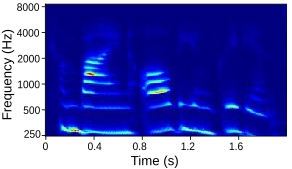 |
|
| Fully trained with source features | 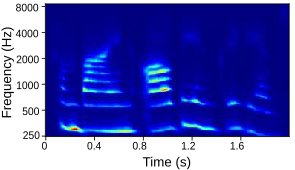 |
|
| Fully trained ‘without’ source features | 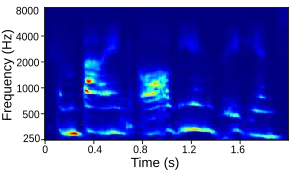 |
|
| Lightly trained with source features | 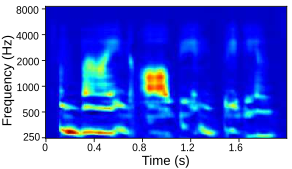 |
| Description | Audio | Auditory spectrogram |
|---|---|---|
| Input Audio (Male) | 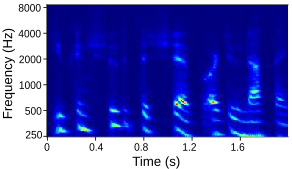 |
|
| Fully trained with source features |  |
|
| Fully trained ‘without’ source features | 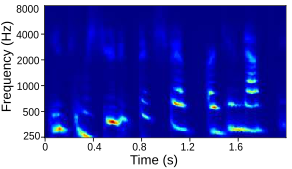 |
|
| Lightly trained with source features |  |
2. MirrorNet with the articulatory synthesizer
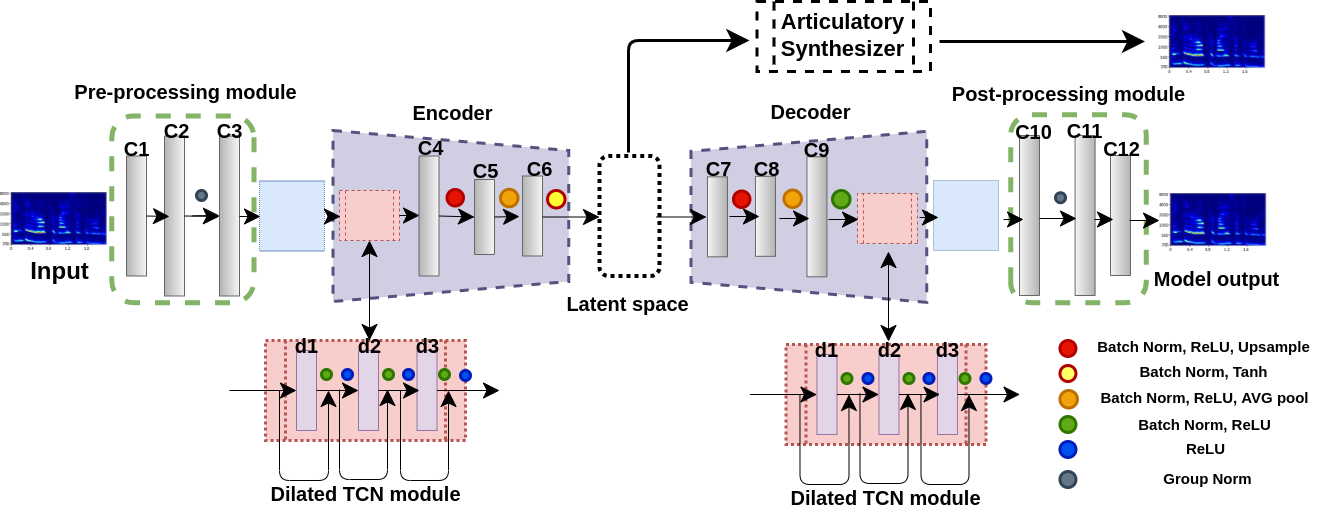
– Auditory spectrograms and audio samples
Tables below show output auditory spectrograms and their corresponding acoustic output obtained by inverting the auditory spectrograms. Here the articulatory synthesizers developed in the previous step are used as the vocal tract model in the MirrorNet. The results are from unseen speech utterenaces in the test split of the XRMB dataset.
| Description | Audio | Auditory spectrogram |
|---|---|---|
| Input Audio | 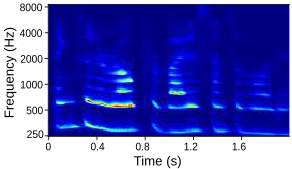 |
|
| With Initialization and Fully trained synthesizer | 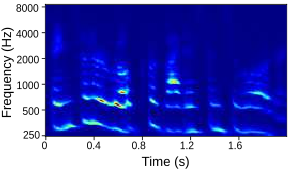 |
|
| ‘No’ Initialization and Fully trained synthesizer |  |
|
| With Initialization and lightly trained synthesizer |  |
| Description | Audio | Auditory spectrogram |
|---|---|---|
| Input Audio | 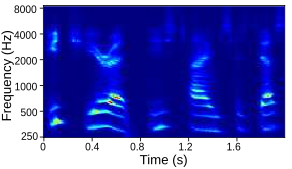 |
|
| With Initialization and Fully trained synthesizer | 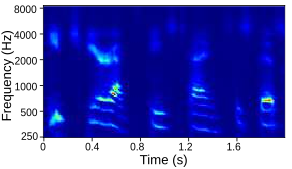 |
|
| ‘No’ Initialization and Fully trained synthesizer |  |
|
| With Initialization and lightly trained synthesizer |  |